
Discovering and documenting rule patterns is the key to an easy to maintain and reliable system. A key Red Hat document is “Design Patterns in Production Systems” by Wolfgang Laun. An efficiency gain of x3 for analysis, development and maintenance is achievable.
The idea is to identify similar rules in the analysis and group them together. This is usually straightforward:
Before Grouping:
when pcode 12387384 and approval documents < 3 then use pcode 34897383 when pcode 13443455 and approval documents < 3 then use pcode 45455333 when pcode 45454334 and approval documents < 3 then use pcode 44546777 etc
After Grouping:
when <old_pcode> and approval documents < 3 then use <new_pcode>
This simple technique then allows you to create a single generic rule, called “supersede” in this example, replacing all the existing rules. In addition, the simplified input for the rules means that business users can easily understand the code, successfully modify, and even add new rules.
Here is one of the old rules (DROOLS example):
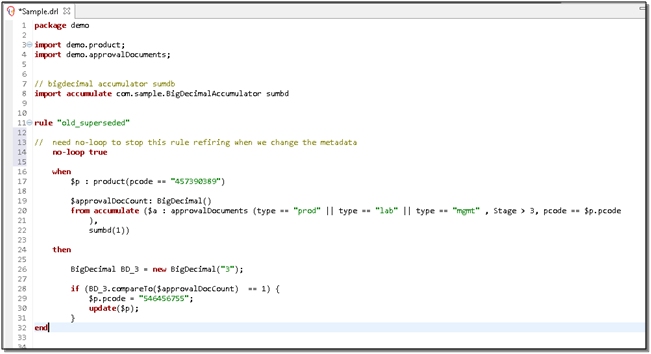
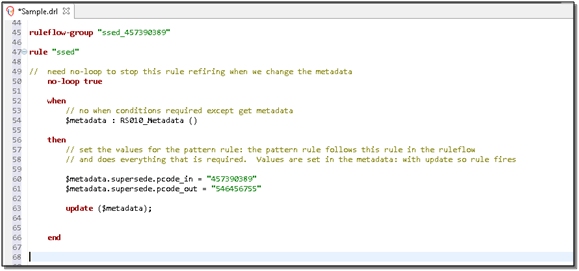
And is replaced with this much simpler rule: the person who maintains this rule does not have to worry about the intricacies of DROOLS accumulate, BigDecimal, and so on: just two simple lines to maintain.
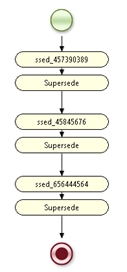
Below is a ruleflow, showing three of these rules, and the re-use of the complex code in the pattern rule (called supersede):
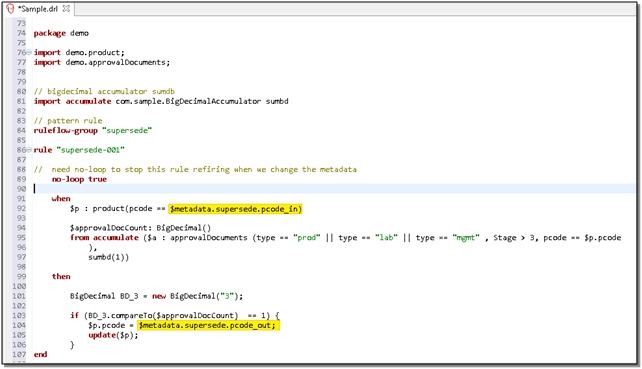
Existing systems can easily be re-factored to take advantage of this architecture: simply replace the original values with the new metadata – in this case a two line change (highlighted in yellow), as this demo pattern rule shows:
Other points of note are:
- The pattern rules can be the subject of further generalization, to include other options and patterns, all with the benefit of reducing code.
– - The use of repeated pattern rules in ruleflows also can improve performance too: DROOLS automatically checks repeated rules, and only reruns them if there has been a change in the data.
.